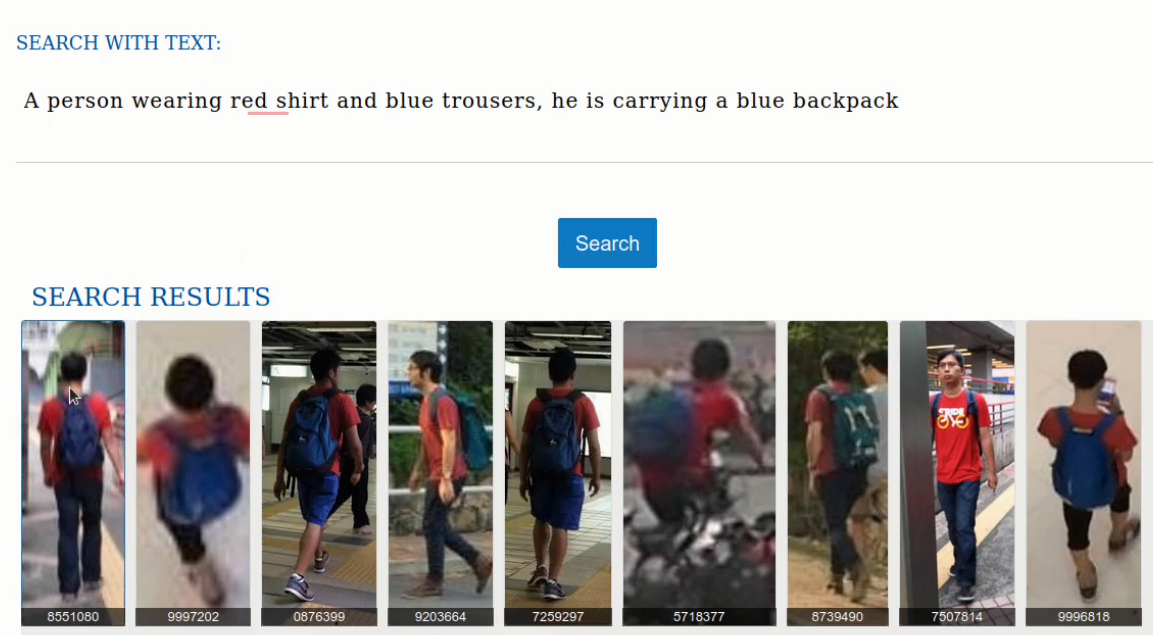
Person Re-Identification
Given a picture of a person, the aim of Person Re-ID is to identify the same person across different cameras. Often done with images and videos, this demo also uses natural language description of a person to spot the person of interest more reliably. This can be helpful in many security applications such as identifying a criminal from a witness description. Person re-identification (Re-ID) comes with many challenges like motion blur, illumination changes, background changes, pose variations, different image resolutions, occlusions, etc. Standard Person Re-ID assumes a query image/video to be searched from a large pool of gallery images/videos. In practical scenarios like crime investigations, often we only have information in the form of language description of a person. This demo shows a better Person Re-ID system using both vision and language to learn a joint embedding space for retrieval. It is based on free-form descriptions, instead of attribute based approach, requiring fewer constraints on textual annotations. While describing something we are not sure of we can give a fuzzy description e.g., ‘perhaps wearing a gold watch or a bracelet’.